Blog interesante
http://profe-alexz.blogspot.mx/2011/12/distribucion-normal-problemas-resueltos.html
viernes, 13 de mayo de 2016
sábado, 30 de abril de 2016
jueves, 17 de marzo de 2016
Regresión Lineal Simple
El análisis de regresión es una técnica estadística para investigar la relación
funcional entre dos o más variables, ajustando algún modelo matemático.
La regresión lineal simple utiliza una sola variable de regresión y el caso más
sencillo es el modelo de línea recta. Supóngase que se tiene un conjunto de n
pares de observaciones (xi,yi), se busca encontrar una recta que describa de la
mejor manera cada uno de esos pares observados.
https://youtu.be/rFLgLOsU1LM
https://youtu.be/4PiiSUxcalg
https://youtu.be/kYGPpxhDiks
lunes, 29 de febrero de 2016
Hipótesis
Una hipótesis (del latín hypothĕsis y este del griego ὑπόθεσις) es una «suposición de algo posible o imposible para sacar de ello una consecuencia».1 Es una idea que puede no ser verdadera, basada en información previa. Su valor reside en la capacidad para establecer más relaciones entre los hechos y explicar por qué se producen. Normalmente se plantean primero las razones claras por las que uno cree que algo es posible. Y finalmente ponemos: en conclusión. Este método se usa en el método científico, para luego comprobar las hipótesis a través de los experimentos.
Una hipótesis científica es una proposición aceptable que ha sido formulada a través de la recolección de información y datos, aunque no esté confirmada, sirve para responder de forma alternativa a un problema con base científica.
Una hipótesis puede usarse como una propuesta provisional que no se pretende demostrar estrictamente, o puede ser una predicción que debe ser verificada por el método científico. En el primer caso, el nivel de veracidad que se otorga a una hipótesis dependerá de la medida en que los datos empíricos apoyan lo afirmado en la hipótesis. Esto es lo que se conoce como contrastación empírica de la hipótesis o bien proceso de validación de la hipótesis. Este proceso puede realizarse mediante confirmación(para las hipótesis universales) o mediante verificación (para las hipótesis existenciales).
Aspecto de la hipótesis
Como se ha dicho, una hipótesis es una conjetura posible que se establece en forma de proposición afirmativa, en futuro simple o en condicional. Una hipótesis no se establece en forma de pregunta, como por ejemplo: ¿pueden los gansos sobrepasar los 85 km/h volando? sino que de una suposición, de la que se cree que es algo viable y veraz, se afirma por ejemplo que: los gansos pueden sobrepasar volando los 85 km/h; o bien se asegura que: los gansos sobrepasarán volando los 85 km/h; o bien: si un grupo de gansos escogido puede superar los 85 km/h, entonces podremos concluir que los gansos pueden sobrepasar volando los 85 km/h.
Además, especialmente desde Karl Popper, se ha insistido en que las hipótesis formuladas deben ser falsables, es decir, deben estar formuladas de una forma clara que permita construir un experimento que potencialmente pueda corroborar o contradecir la hipótesis. Si bien, diversas críticas al falsacionismo más simplista, han señalado que la falsabilidad no es una condición suficiente, aunque generalmente necesaria.
Hipótesis nula: Ho: rxy = 0 (no hay relación entre...)
Hipótesis alternativa: H1: rxy 0 (existe relación entre...)
Hipótesis alternativa: H1: rxy 0 (existe relación entre...)
En un estudio de investigación, el error de tipo I también denominado error de tipo alfa (α)1 o falso positivo, es el error que se comete cuando el investigador no acepta la hipótesis nula (H_0) siendo esta verdadera en la población.
En un estudio de investigación, el error de tipo II, también llamado error de tipo beta (β) (β es la probabilidad de que exista este error) o falso negativo, se comete cuando el investigador no rechaza la hipótesis nula siendo esta falsa en la población.
https://es.wikipedia.org/wiki/Errores_de_tipo_I_y_de_tipo_II
En un estudio de investigación, el error de tipo II, también llamado error de tipo beta (β) (β es la probabilidad de que exista este error) o falso negativo, se comete cuando el investigador no rechaza la hipótesis nula siendo esta falsa en la población.
https://es.wikipedia.org/wiki/Errores_de_tipo_I_y_de_tipo_II
viernes, 26 de febrero de 2016
Tamaño de la muestra
http://www.netquest.com/blog/es/que-tamano-de-muestra-necesito/
http://www.monografias.com/trabajos87/calculo-del-tamano-muestra/calculo-del-tamano-muestra.shtml
lunes, 22 de febrero de 2016
Niveles de confianza
El nivel de confianza es la probabilidad de que el parámetro a estimar se encuentre en el intervalo de confianza.
El nivel de confianza (p) se designa mediante 1 − α, y se suele tomar en tanto por ciento.
Los niveles de confianza más usuales son: 90%; 95% y 99%.
El nivel de significación se designa mediante α.
El valor crítico (k) como z α/2 .
P(Z>z α/2) = α/2
P[-z α/2 < z < z α/2] = 1 - α
De lo cual se obtendrá el intervalo de confianza:
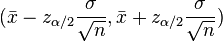
Obsérvese que el intervalo de confianza viene dado por la media muestral 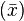 ± el producto del valor crítico
± el producto del valor crítico 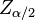 por el error estándar
por el error estándar  .
.
± el producto del valor crítico por el error estándar .
Calculadora Intervalo de confianza
http://es.ncalculators.com/statistics/confidence-interval-calculadora.htm
Video
https://youtu.be/qfhtjcgnoGg
https://youtu.be/YDFzX4fT1BU
Video
https://youtu.be/qfhtjcgnoGg
https://youtu.be/YDFzX4fT1BU
lunes, 11 de enero de 2016
Desviación Estandar
Desviación estandar o típica
https://www.youtube.com/watch?v=YC9158GWkpY
https://www.youtube.com/watch?v=CdrhTnzGk9o
La desviación típica o desviación estándar (denotada con el símbolo σ o s, dependiendo de la procedencia del conjunto de datos) es una medida de dispersión para variables de razón (variables cuantitativas o cantidades racionales) y de intervalo. Se define como la raíz cuadrada de la varianza de la variable.
Para conocer con detalle un conjunto de datos, no basta con conocer las medidas de tendencia central, sino que necesitamos conocer también la desviación que presentan los datos en su distribución respecto de la media aritmética de dicha distribución, con objeto de tener una visión de los mismos más acorde con la realidad al momento de describirlos e interpretarlos para la toma de decisiones.
La desviación típica es una medida del grado de dispersión de los datos con respecto al valor promedio. Dicho de otra manera, la desviación estándar es simplemente el "promedio" o variación esperada con respecto a la media aritmética.
Por ejemplo, las tres muestras (0, 0, 14, 14), (0, 6, 8, 14) y (6, 6, 8, 8) cada una tiene una media de 7. Sus desviaciones estándar poblacionales son 7, 5 y 1, respectivamente. La tercera muestra tiene una desviación mucho menor que las otras dos porque sus valores están más cerca de 7.
Desviación Estandar n-1 (muestra) y como interpretarla
Varianza
Desviación Estandar n-1 (muestra) y como interpretarla
Varianza
En teoría de probabilidad, la varianza (que suele representarse como  ) de una variable aleatoria es una medida de dispersión definida como la esperanza del cuadrado de la desviación de dicha variable respecto a su media.
) de una variable aleatoria es una medida de dispersión definida como la esperanza del cuadrado de la desviación de dicha variable respecto a su media.
) de una variable aleatoria es una medida de dispersión definida como la esperanza del cuadrado de la desviación de dicha variable respecto a su media.
Está medida en unidades distintas de las de la variable. Por ejemplo, si la variable mide una distancia en metros, la varianza se expresa en metros al cuadrado. La desviación estándar es la raíz cuadrada de la varianza, es una medida de dispersión alternativa expresada en las mismas unidades de los datos de la variable objeto de estudio. La varianza tiene como valor mínimo 0.
Hay que tener en cuenta que la varianza puede verse muy influida por los valores atípicos y no se aconseja su uso cuando las distribuciones de las variables aleatorias tienen colas pesadas. En tales casos se recomienda el uso de otras medidas de dispersión másrobustas.
Videos
Muestra
Muestra Estadística
Las muestras se obtienen con la intención de inferir propiedades de la totalidad de la población, para lo cual deben ser representativas de la misma. Para cumplir esta característica la inclusión de sujetos en la muestra debe seguir una técnica de muestreo. En tales casos, puede obtenerse una información similar a la de un estudio exhaustivo con mayor rapidez y menor coste
Nivel de confianza
https://www.youtube.com/watch?v=F8Mea-3UJ2k
Las muestras se obtienen con la intención de inferir propiedades de la totalidad de la población, para lo cual deben ser representativas de la misma. Para cumplir esta característica la inclusión de sujetos en la muestra debe seguir una técnica de muestreo. En tales casos, puede obtenerse una información similar a la de un estudio exhaustivo con mayor rapidez y menor coste
Nivel de confianza
El nivel de confianza se indica por 1-α y habitualmente se da en porcentaje (1-α)%. Hablamos de nivel de confianza y no de probabilidad (la probabilidad implica eventos aleatorios) ya que una vez extraída la muestra, el intervalo de confianza estará definido al igual que la media poblacional (μ)y solo se confía si contendrá al verdadero valor del parámetro o no, lo que si conlleva una probabilidad es que si repetimos el proceso con muchas medias muestrales podríamos afirmar que el (1-α)% de los intervalos así construidos contendría al verdadero valor del parámetro.
Los valores que se suelen utilizar para el nivel de confianza son el 95%, 99% y 99,9%
Videos
viernes, 8 de enero de 2016
Error Estandar
Error Estandar
Definición
El Error estándar es el término utilizado para referirse a una estimación de la desviación estándar, derivado de una muestra especial utilizada para calcular la estimación en las estadísticas. En la más común, error estándar es un proceso de estimación de la desviación estándar de la distribución de muestreo asociada con el método de estimación
Cada estadística tiene un error estándar asociado. Una medida de la precisión de la estadística puede deducir que el error estándar de 0 representa que la estadística tiene ningún error aleatorio y el más grande representa menos preciso de las estadísticas. Error estándar no es constantemente informados y no siempre fáciles de calcular.
Wiki Error Estandar
 (1)
(1)
 (2)
(2)
 (3)
(3)
 (4)
(4)
 (5)
(5)
 (6)
(6)
Definición
El Error estándar es el término utilizado para referirse a una estimación de la desviación estándar, derivado de una muestra especial utilizada para calcular la estimación en las estadísticas. En la más común, error estándar es un proceso de estimación de la desviación estándar de la distribución de muestreo asociada con el método de estimación
Cada estadística tiene un error estándar asociado. Una medida de la precisión de la estadística puede deducir que el error estándar de 0 representa que la estadística tiene ningún error aleatorio y el más grande representa menos preciso de las estadísticas. Error estándar no es constantemente informados y no siempre fáciles de calcular.
Wiki Error Estandar
La media muestral es el estimador usual de una media poblacional. Sin embargo, diferentes muestras escogidas de la misma población tienden en general a dar distintos valores de medias muestrales. Elerror estándar de la media (es decir, el error debido a la estimación de la media poblacional a partir de las medias muestrales) es la desviación estándar de todas las posibles muestras (de un tamaño dado) escogidos de esa población. Además, el error estándar de la media puede referirse a una estimación de la desviación estándar, calculada desde una muestra de datos que está siendo analizada al mismo tiempo.
En aplicaciones prácticas, el verdadero valor de la desviación estándar (o del error) es generalmente desconocido. Como resultado, el término "error estándar" se usa a veces para referirse a una estimación de esta cantidad desconocida. En tales casos es importante tener claro de dónde proviene, ya que el error estándar es sólo una estimación. Desafortunadamente, esto no es siempre posible y puede ser mejor usar una aproximación que evite usar el error estándar, por ejemplo usando la estimación de máxima verosimilitud o una aproximación más formal derivada de los intervalos de confianza. Un caso bien conocido donde se pueda usar de forma apropiada puede ser en la distribución t de Student para proporcionar un intervalo de confianza para una media estimada o diferencia de medias. En otros casos, el error estándar puede ser usado para proveer una indicación del tamaño de la incertidumbre, pero su uso formal o semi-formal para proporcionar intervalos de confianza o test debe ser evitado a menos que el tamaño de la muestra sea al menos moderadamente grande. Aquí el concepto "grande" dependerá de las cantidades particulares que vayan a ser analizadas.
En análisis de regresión, el término error estándar o error típico es también usado como la media de las diferencias entre la estimación por mínimos cuadrados y los valores dados de la muestra2 3
El concepto del error estándar
Medición de un error aleatorio en un dato estadístico informado
: ¿Qué es el error estándar y cómo se lo utiliza en la práctica?
R: Uno de los conceptos más útiles en la práctica estadística es justamente el de "error estándar". Este término fue definido originalmente por el estadístico británico Udny Yule a comienzos del siglo XX. La norma E2586 de ASTM, Práctica para calcular y usar estadísticas básicas, define el error estándar como "la desviación estándar de la población de valores de una estadística muestral en un muestreo repetido o su estimación". El término incertidumbre está estrechamente relacionado con el error estándar y en las últimas décadas se la he dedicado bastante atención. El error estándar mide el error aleatorio en un dato estadístico informado: el tipo de error causado por la variación aleatoria del muestreo al repetir una prueba en las mismas condiciones. La incertidumbre es un concepto más amplio que incluye componentes adicionales de error potencial además del error aleatorio. La norma E2655 de ASTM, Guía para informar la incertidumbre de los resultados de pruebas y Uso del término incertidumbre de la medición en métodos de prueba de ASTM, describe el uso del concepto de incertidumbre tal como se lo aplica al resultado de una prueba.
En general, las personas que toman las decisiones y los usuarios que utilizan los datos suelen estar más preocupados por los datos estadísticos que por las mediciones individuales en un grupo de datos. Los usuarios de datos desean ver promedios, varianzas, rangos, proporciones, valores máximos o mínimos, percentilos u otras estadísticas. Lo que a menudo no logran apreciar totalmente es que las estadísticas también se comportan de una manera aleatoria, similar a la de las mediciones individuales, y esto se mide con el error estándar. Cuando se informa la media de una muestra, no se informa el promedio "verdadero" sino una estimación. La estadística muestral puede resultar levemente superior o inferior al valor verdadero desconocido. El error estándar de la media mide la diferencia que puede existir entre la media verdadera y la estadística que se informa. En términos más generales, podemos hablar del "error estándar de la estimación" cada vez que se informa una cantidad estadística estimada. Cuando se calcula un dato estadístico único, es posible calcular el error estándar de la estimación. En general, cuanto mayor sea el tamaño de la muestra, menor será el error estándar de una cantidad estimada.
Para ver cómo funciona esto, analicemos una media muestral. A partir de una muestra de tamaño n, se calculan la media muestral y la desviación estándar. En realidad hay una media verdadera, μ, y una desviación estándar verdadera σ, y son desconocidas. La muestra nos brinda las estimaciones  y S. Si hiciéramos muestras repetidamente de la población/proceso del cual se toma la muestra y calculáramos la media muestral una y otra vez, la desviación estándar de la distribución de medias sería el error estándar verdadero de la media. En teoría, esta es la Ecuación 1:
y S. Si hiciéramos muestras repetidamente de la población/proceso del cual se toma la muestra y calculáramos la media muestral una y otra vez, la desviación estándar de la distribución de medias sería el error estándar verdadero de la media. En teoría, esta es la Ecuación 1:
Debido a que solo tenemos una media estimada, y no conocemos el verdaderos σ, solo podemos estimar el error estándar como:
El error en un resultado informado se llama error de muestreo, y se mide como desviación absoluta del valor verdadero desconocido. Por lo tanto, para una media, el error muestral puede considerarse como la desviación | - μ| . Alrededor del 68% de las veces el error muestral tendrá como máximo el tamaño de un error estándar, y en el 95% de los casos, el de 2 errores estándar. Esto puede expresarse más concisamente de la siguiente manera:
- μ| . Alrededor del 68% de las veces el error muestral tendrá como máximo el tamaño de un error estándar, y en el 95% de los casos, el de 2 errores estándar. Esto puede expresarse más concisamente de la siguiente manera:
- μ| . Alrededor del 68% de las veces el error muestral tendrá como máximo el tamaño de un error estándar, y en el 95% de los casos, el de 2 errores estándar. Esto puede expresarse más concisamente de la siguiente manera:
De este modo, el usuario de una estadística obtiene una idea de la magnitud de la diferencia que pudo haberse verificado en la práctica, la manera en que el tamaño de la muestra afecta el posible error de una estimación y con qué probabilidad aproximada (confianza). En este caso, estamos considerando un tamaño de muestra de 20 o más y estamos usando la teoría de la distribución normal. Algunos lectores también reconocerán en esto una cierta similitud con la construcción de un intervalo de confianza para una media desconocida. En la norma E2586 de ASTM se tratan los intervalos de confianza y se ha publicado un artículo de DataPoints sobre este tema.1
Ejemplos
Consideremos que en una muestra de tamaño n = 20 se determinó que la media muestral y la desviación estándar eran 162 y 11,5 respectivamente. El error estándar estimado de la media surge de la Ecuación 2: 11,5/4,47 = 2,57. De este modo, el potencial de error en el resultado informado no es superior a ±2,57 (68% de confianza) o no más de 2(2,57) = ±5,14 (a 95% de confianza).
Uno de los recursos estadísticos más utilizados es una proporción simple. Hay una muestra de objetos de tamaño n, y se observa cada objeto para identificar la ocurrencia de un atributo. Cada objeto tiene o no tiene el atributo. Esta es la situación, por ejemplo, en los muestreos de control de calidad o en las encuestas de opinión pública. La estadística, indicada  , es la proporción en la muestra que tiene ese atributo. La proporción verdadera y desconocida de todos los objetos es p. El error estándar teórico de la estimación es:
, es la proporción en la muestra que tiene ese atributo. La proporción verdadera y desconocida de todos los objetos es p. El error estándar teórico de la estimación es:
En la práctica no conocemos nunca el valor verdadero de p, de modo que reemplazamos la estadística y obtenemos una estimación del error estándar. Utilizando la Ecuación 5, el error estándar estimado es:
Cuando esta técnica se utiliza en una encuesta política o una investigación de mercado, la cantidad 2SE()se menciona como margen de error de la encuesta. Supongamos que en una muestra de n = 200 componentes de metal inspeccionados, se clasificaron 23 como defectuosos. La estimación de la proporción defectuosa del proceso es = 23/200 = 0,115 o 11,5%.
El error estándar de esta estimación, usando la Ecuación 6, es 0.0226 o 2,26%. En caso de querer reclamar una confianza de aproximadamente 95% en el posible error en el resultado, deberíamos informarlo utilizando dos errores estándar o como 11,5% ±4,52%. De todos modos, debería informarse al menos el error estándar (2,26%) junto con la estimación.
En la E2586 de ASTM están disponibles las fórmulas de error estándar para varios casos comunes. En la bibliografía sobre ciencias estadísticas pueden consultarse otros casos y métodos.
Referencias
1. Stephen N. Luko y Dean V. Neubauer, “Statistical Intervals, Part 1: The Confidence Interval,” ASTM Standardization News, Vol. 39, Núm. 4, julio/agosto 2011.
1. Stephen N. Luko y Dean V. Neubauer, “Statistical Intervals, Part 1: The Confidence Interval,” ASTM Standardization News, Vol. 39, Núm. 4, julio/agosto 2011.
Stephen N. Luko, de Hamilton Sundstrand, Windsor Locks, Connecticut, es el anterior presidente del Comité E11 sobre calidad y estadísticas y es miembro de ASTM International.
Dean V. Neubauer, de Corning Inc., Corning, Nueva York, es miembro de ASTM; se desempeña como vicepresidente del Comité E11 sobre calidad y estadísticas, es presidente del Subcomité E11.30 sobre control estadístico de la calidad y del E11.90.03 sobre publicaciones, y también coordina la columna DataPoints (Mediciones).
Videos
https://youtu.be/u_3laV-TTgg
https://www.youtube.com/watch?v=ZWkp95WTBhc
https://www.youtube.com/watch?v=ZWkp95WTBhc
Suscribirse a:
Entradas (Atom)