Blog interesante
http://profe-alexz.blogspot.mx/2011/12/distribucion-normal-problemas-resueltos.html
viernes, 13 de mayo de 2016
sábado, 30 de abril de 2016
jueves, 17 de marzo de 2016
Regresión Lineal Simple
El análisis de regresión es una técnica estadística para investigar la relación
funcional entre dos o más variables, ajustando algún modelo matemático.
La regresión lineal simple utiliza una sola variable de regresión y el caso más
sencillo es el modelo de línea recta. Supóngase que se tiene un conjunto de n
pares de observaciones (xi,yi), se busca encontrar una recta que describa de la
mejor manera cada uno de esos pares observados.
https://youtu.be/rFLgLOsU1LM
https://youtu.be/4PiiSUxcalg
https://youtu.be/kYGPpxhDiks
lunes, 29 de febrero de 2016
Hipótesis
Una hipótesis (del latín hypothĕsis y este del griego ὑπόθεσις) es una «suposición de algo posible o imposible para sacar de ello una consecuencia».1 Es una idea que puede no ser verdadera, basada en información previa. Su valor reside en la capacidad para establecer más relaciones entre los hechos y explicar por qué se producen. Normalmente se plantean primero las razones claras por las que uno cree que algo es posible. Y finalmente ponemos: en conclusión. Este método se usa en el método científico, para luego comprobar las hipótesis a través de los experimentos.
Una hipótesis científica es una proposición aceptable que ha sido formulada a través de la recolección de información y datos, aunque no esté confirmada, sirve para responder de forma alternativa a un problema con base científica.
Una hipótesis puede usarse como una propuesta provisional que no se pretende demostrar estrictamente, o puede ser una predicción que debe ser verificada por el método científico. En el primer caso, el nivel de veracidad que se otorga a una hipótesis dependerá de la medida en que los datos empíricos apoyan lo afirmado en la hipótesis. Esto es lo que se conoce como contrastación empírica de la hipótesis o bien proceso de validación de la hipótesis. Este proceso puede realizarse mediante confirmación(para las hipótesis universales) o mediante verificación (para las hipótesis existenciales).
Aspecto de la hipótesis
Como se ha dicho, una hipótesis es una conjetura posible que se establece en forma de proposición afirmativa, en futuro simple o en condicional. Una hipótesis no se establece en forma de pregunta, como por ejemplo: ¿pueden los gansos sobrepasar los 85 km/h volando? sino que de una suposición, de la que se cree que es algo viable y veraz, se afirma por ejemplo que: los gansos pueden sobrepasar volando los 85 km/h; o bien se asegura que: los gansos sobrepasarán volando los 85 km/h; o bien: si un grupo de gansos escogido puede superar los 85 km/h, entonces podremos concluir que los gansos pueden sobrepasar volando los 85 km/h.
Además, especialmente desde Karl Popper, se ha insistido en que las hipótesis formuladas deben ser falsables, es decir, deben estar formuladas de una forma clara que permita construir un experimento que potencialmente pueda corroborar o contradecir la hipótesis. Si bien, diversas críticas al falsacionismo más simplista, han señalado que la falsabilidad no es una condición suficiente, aunque generalmente necesaria.
Hipótesis nula: Ho: rxy = 0 (no hay relación entre...)
Hipótesis alternativa: H1: rxy 0 (existe relación entre...)
Hipótesis alternativa: H1: rxy 0 (existe relación entre...)
En un estudio de investigación, el error de tipo I también denominado error de tipo alfa (α)1 o falso positivo, es el error que se comete cuando el investigador no acepta la hipótesis nula (H_0) siendo esta verdadera en la población.
En un estudio de investigación, el error de tipo II, también llamado error de tipo beta (β) (β es la probabilidad de que exista este error) o falso negativo, se comete cuando el investigador no rechaza la hipótesis nula siendo esta falsa en la población.
https://es.wikipedia.org/wiki/Errores_de_tipo_I_y_de_tipo_II
En un estudio de investigación, el error de tipo II, también llamado error de tipo beta (β) (β es la probabilidad de que exista este error) o falso negativo, se comete cuando el investigador no rechaza la hipótesis nula siendo esta falsa en la población.
https://es.wikipedia.org/wiki/Errores_de_tipo_I_y_de_tipo_II
viernes, 26 de febrero de 2016
Tamaño de la muestra
http://www.netquest.com/blog/es/que-tamano-de-muestra-necesito/
http://www.monografias.com/trabajos87/calculo-del-tamano-muestra/calculo-del-tamano-muestra.shtml
lunes, 22 de febrero de 2016
Niveles de confianza
El nivel de confianza es la probabilidad de que el parámetro a estimar se encuentre en el intervalo de confianza.
El nivel de confianza (p) se designa mediante 1 − α, y se suele tomar en tanto por ciento.
Los niveles de confianza más usuales son: 90%; 95% y 99%.
El nivel de significación se designa mediante α.
El valor crítico (k) como z α/2 .
P(Z>z α/2) = α/2
P[-z α/2 < z < z α/2] = 1 - α
De lo cual se obtendrá el intervalo de confianza:
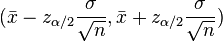
Obsérvese que el intervalo de confianza viene dado por la media muestral 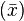 ± el producto del valor crítico
± el producto del valor crítico 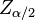 por el error estándar
por el error estándar  .
.
± el producto del valor crítico por el error estándar .
Calculadora Intervalo de confianza
http://es.ncalculators.com/statistics/confidence-interval-calculadora.htm
Video
https://youtu.be/qfhtjcgnoGg
https://youtu.be/YDFzX4fT1BU
Video
https://youtu.be/qfhtjcgnoGg
https://youtu.be/YDFzX4fT1BU
lunes, 11 de enero de 2016
Desviación Estandar
Desviación estandar o típica
https://www.youtube.com/watch?v=YC9158GWkpY
https://www.youtube.com/watch?v=CdrhTnzGk9o
La desviación típica o desviación estándar (denotada con el símbolo σ o s, dependiendo de la procedencia del conjunto de datos) es una medida de dispersión para variables de razón (variables cuantitativas o cantidades racionales) y de intervalo. Se define como la raíz cuadrada de la varianza de la variable.
Para conocer con detalle un conjunto de datos, no basta con conocer las medidas de tendencia central, sino que necesitamos conocer también la desviación que presentan los datos en su distribución respecto de la media aritmética de dicha distribución, con objeto de tener una visión de los mismos más acorde con la realidad al momento de describirlos e interpretarlos para la toma de decisiones.
La desviación típica es una medida del grado de dispersión de los datos con respecto al valor promedio. Dicho de otra manera, la desviación estándar es simplemente el "promedio" o variación esperada con respecto a la media aritmética.
Por ejemplo, las tres muestras (0, 0, 14, 14), (0, 6, 8, 14) y (6, 6, 8, 8) cada una tiene una media de 7. Sus desviaciones estándar poblacionales son 7, 5 y 1, respectivamente. La tercera muestra tiene una desviación mucho menor que las otras dos porque sus valores están más cerca de 7.
Desviación Estandar n-1 (muestra) y como interpretarla
Varianza
Desviación Estandar n-1 (muestra) y como interpretarla
Varianza
En teoría de probabilidad, la varianza (que suele representarse como  ) de una variable aleatoria es una medida de dispersión definida como la esperanza del cuadrado de la desviación de dicha variable respecto a su media.
) de una variable aleatoria es una medida de dispersión definida como la esperanza del cuadrado de la desviación de dicha variable respecto a su media.
) de una variable aleatoria es una medida de dispersión definida como la esperanza del cuadrado de la desviación de dicha variable respecto a su media.
Está medida en unidades distintas de las de la variable. Por ejemplo, si la variable mide una distancia en metros, la varianza se expresa en metros al cuadrado. La desviación estándar es la raíz cuadrada de la varianza, es una medida de dispersión alternativa expresada en las mismas unidades de los datos de la variable objeto de estudio. La varianza tiene como valor mínimo 0.
Hay que tener en cuenta que la varianza puede verse muy influida por los valores atípicos y no se aconseja su uso cuando las distribuciones de las variables aleatorias tienen colas pesadas. En tales casos se recomienda el uso de otras medidas de dispersión másrobustas.
Videos
Suscribirse a:
Entradas (Atom)